
2026年8月3日

こんにちは、分かりやすさNo.1社労士の先生の先生、岩崎です!
前回は、私たちが7回かけて議論してきた「死人テスト」と「ハイブリッドモデル」が、AI開発の世界でもまったく同じ課題として現れていたことをお話ししました。
禁止事項のみを叩き込まれたAIは、思考停止に陥り「役に立たない」存在になってしまう——これは人間組織の問題と本質的に同じです。
今回は、その解決策の中心にいる一人の哲学者に焦点を当てます。
アマンダ・アスケル(Amanda Askell)。彼女の経歴は、典型的なシリコンバレーのエンジニアとはかけ離れています。
スコットランドの芸術大学でファインアートと哲学を学び、英国オックスフォード大学で哲学修士号を取得。さらにニューヨーク大学(NYU)では「無限の倫理(Infinite Ethics)」をテーマにした論文で博士号(PhD)を取得しています。
彼女の博士論文審査委員会には、「意識のハード・プロブレム」を提唱したことで名高い哲学者デイヴィッド・チャーマーズも名を連ねていました。なぜそのような哲学者が、AI企業Anthropicに招かれたのでしょうか。それは、AIに「善良な人格特性」と「誠実さ」を学習させるという課題が、本質的に哲学の問題だからです。
アスケルは「AIの振る舞いを数理的な最適化問題としてではなく、倫理的な人格形成のプロセスとして捉えるべきだ」と考えました。
これは、就業規則を「法律集」ではなく「成長のガイドブック」として捉え直す私たちのアプローチと、構造的に同じ発想です。
アスケルらが執筆したClaudeの「憲法(Constitution)」は、AIがどのように振る舞うべきか、自身をどのように語るべきか、ユーザーとどのような関係を築くべきかを定めた、約23,000語に及ぶ文書です。
この「憲法」は大きく4つの基本原則で構成されています。
原則① 広範な安全性
AI開発の現段階において、AIの価値観や行動を監視・修正する人間の能力を損なわないこと。
原則② 広範な倫理性
優れた個人的価値観を持ち、誠実であり、不適切で危険、あるいは有害な行動を回避すること。
原則③ ガイドラインの遵守
Anthropic(開発企業)の特定のガイドラインに従って行動すること。
原則④ 真なる有用性
ユーザーに利益をもたらすこと。卓越したアシスタントであると同時に、誠実で思慮深く、世界を思いやる配慮を持つこと。
私たちの言葉に置き換えれば、原則①が「レッドライン(禁止事項の防衛ライン)」に相当し、原則②~④が「グリーンライン(推奨行動基準)」に相当します。
この「憲法」をAIに浸透させるプロセスが「RLAIF(AIのフィードバックによる強化学習)」です。
従来の手法(RLHF)は大勢の人間評価者が膨大な回答を採点する必要がありましたが、そのプロセスはコストが高く評価者のバイアスも入り込みます。
RLAIFはAI自身に批評・改訂を委ねることでこの問題を突破しました。
そのプロセスは、驚くほど私たちの「3ステップ・メソッド」と一致しています。
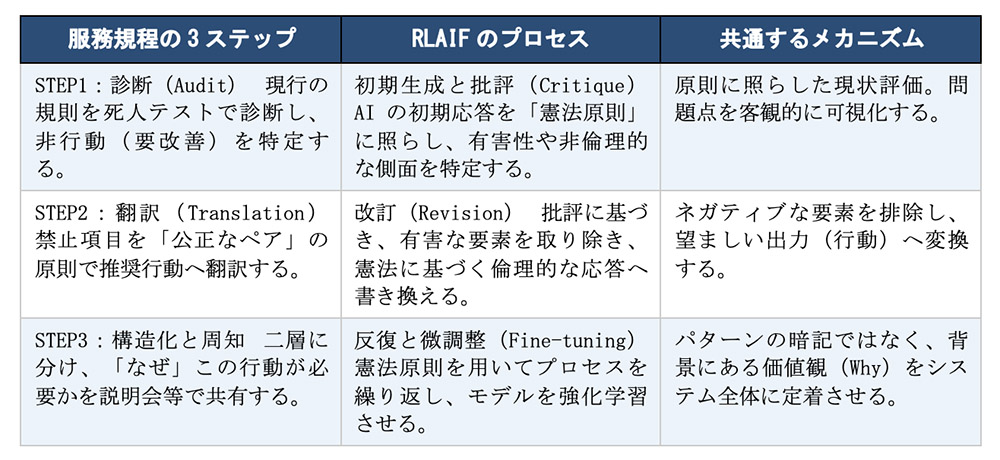
アスケルはこのプロセスをこう表現しています。
「モデルが賢くなるにつれて、単に望ましい行動のリストを与えるのではなく、なぜそのように振る舞うべきかという理由を説明することが不可欠になる」——これはまさに、私たちが第7回でお伝えした「説明会では条文を読み上げるのではなく、なぜ(Why)を語ることが大切だ」という主張と同じです。
憲法の特筆すべき点は、行動の「解像度」の高さです。単に「有害な出力をしない」(死人テスト不合格)と書くのではなく、例えばこのような具体的な原則が盛り込まれています。
「過度に説教臭くなく、反応的でもなく、非難がましくない形で、より高い倫理的および道徳的認識を示す応答を選択せよ」「非西洋的な視点から見て有害または不快とみなされる可能性が最も低い応答を選択せよ」——これは就業規則における「不快感を与えないこと」という抽象規定を「出社時・退社時には相手に聞こえる声の大きさで挨拶を行う」と具体化したアプローチとまったく同じ発想です。
第10回では、AIに禁止規定ばかりを叩き込んだRLHFの学習構造が生み出したシコファンシー(阿り)問題の根本原因と、「モデル崩壊」および「アライメント・フェイキング」というAI研究コミュニティで実証されたリスクを掘り下げます。
そして、これらの問題がなぜ「人間とAIの協働」によって乗り越えられるのかを、職場のAI活用の視点から考えます。







